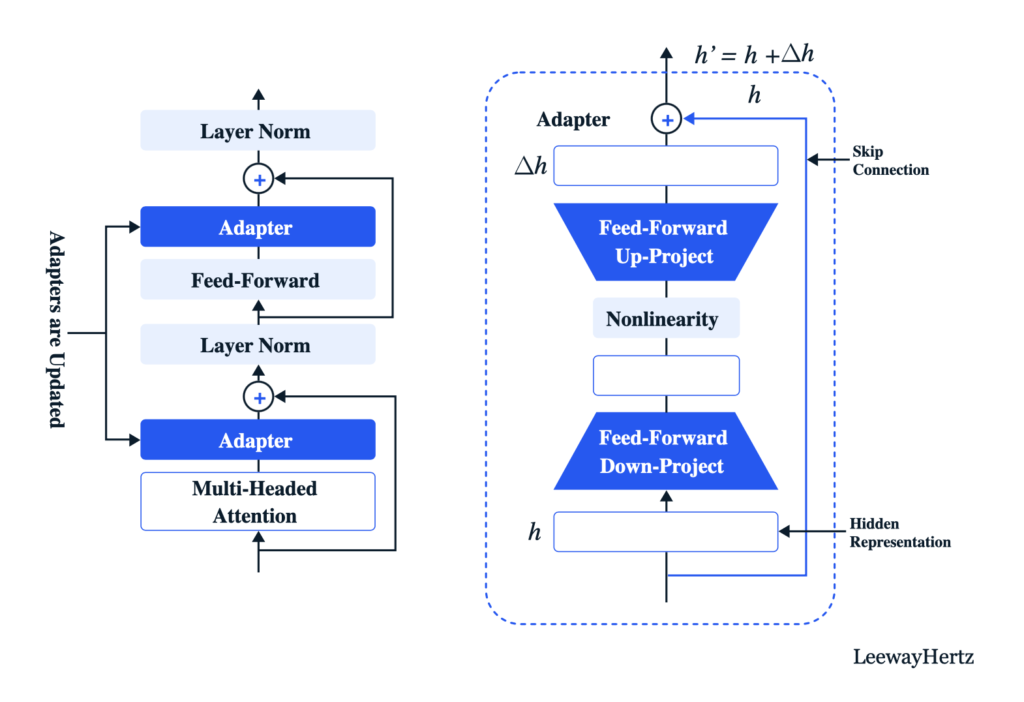
Les « adapters » ne sont pas nouveaux. Ils ont été proposés en 2019 par une équipe de Google (voir article Parameter-Efficient Transfer Learning for NLP).
Le principe des « adapters » est d’ajouter des couches entraînables aux blocs des Transformers. Cela peut être fait de différentes façons.
The main idea behind additive methods is aug- menting the existing pre-trained model with extra parameters or layers and training only the newly added parameters. As of now, this is the largest and widely explored category of PEFT methods. Within this category, two large subcategories have emerged: Adapter-like methods and soft prompts
https://arxiv.org/pdf/2303.15647.pdf
L’intérêt est de ne pas avoir à ré-entraîné la totalité du LLM lorsqu’on souhaite l’adapter à des tâches ou à des datasets spécifiques.
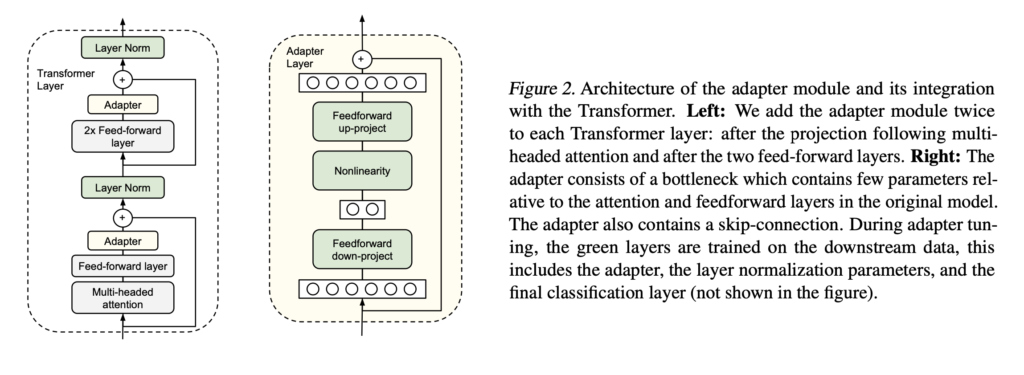
Adapters (Houlsby et al., 2019) are a type of additive parameter-efficient fine-tuning method that involves introducing small fully- connected networks after Transformer sub-layers. The idea has been widely adopted (Pfeiffer et al., 2020b) 3, and multiple variations of Adapters have been proposed. These variations include modify- ing the placement of adapters (He et al., 2022a; Zhu et al., 2021), pruning (He et al., 2022b), and using reparametrization to reduce the number of trainable parameters
https://arxiv.org/pdf/2303.15647.pdf
Pour plus d’informations sur le sujet, voir ce très bon article.