
LoRA (Low-Rank Adaptation ) est une méthode de fine tuning pour LLM. Par fine tuning il faut entendre adaptation du modèle à des tâches ou à un domaine spécifique (par exemple médical).
LoRA comme toutes les méthodes PEFT n’est pas exclusif à Llama 2 mais son utilisation est plus facile avec des LLM open sources.
Similar to the adapters, LoRA is also a small trainable submodule that can be inserted into the transformer architecture. It involves freezing the pre-trained model weights and injecting trainable rank decomposition matrices into each layer of the transformer architecture, greatly diminishing the number of trainable parameters for downstream tasks.
https://www.leewayhertz.com/parameter-efficient-fine-tuning/
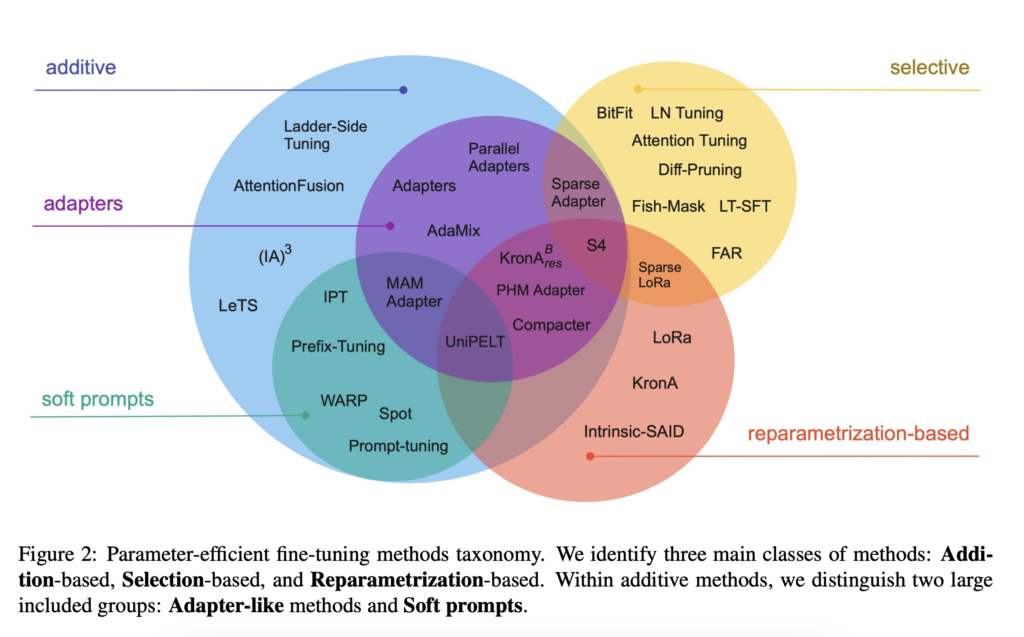
LoRA n’appartient pas à la même catégorie de méthode que les Adapters dans la terminologie proposée par Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning. Les Adapters relèvent des approches additives alors que LoRA est une reparamétrisation.
The implementation of LoRA is relatively straight-forward. We can think of it as a modified forward pass for the fully connected layers in an LLM.
https://lightning.ai/pages/community/tutorial/lora-llm/
How good is LoRA in practice, and how does it compare to full finetuning and other parameter-efficient approaches? According to the LoRA paper, the modeling performance of models using LoRA performs slightly better than models using Adapters, prompt tuning, or prefix tuning across several task-specific benchmarks. Often, LoRA performs even better than finetuning all layers, as shown in the annotated table from the LoRA paper below. (ROUGE is a metric for evaluating language translation performance, I explained it in more detail here.)
https://lightning.ai/pages/community/tutorial/lora-llm/